Beyond Frequencies: Graph Pattern Mining in Multi-weighted Graphs.
Giulia Preti, Matteo Lissandrini, Davide Mottin, Yannis Velegrakis
EDBT 2018
Can we find personalized graph patterns?
TL;DR
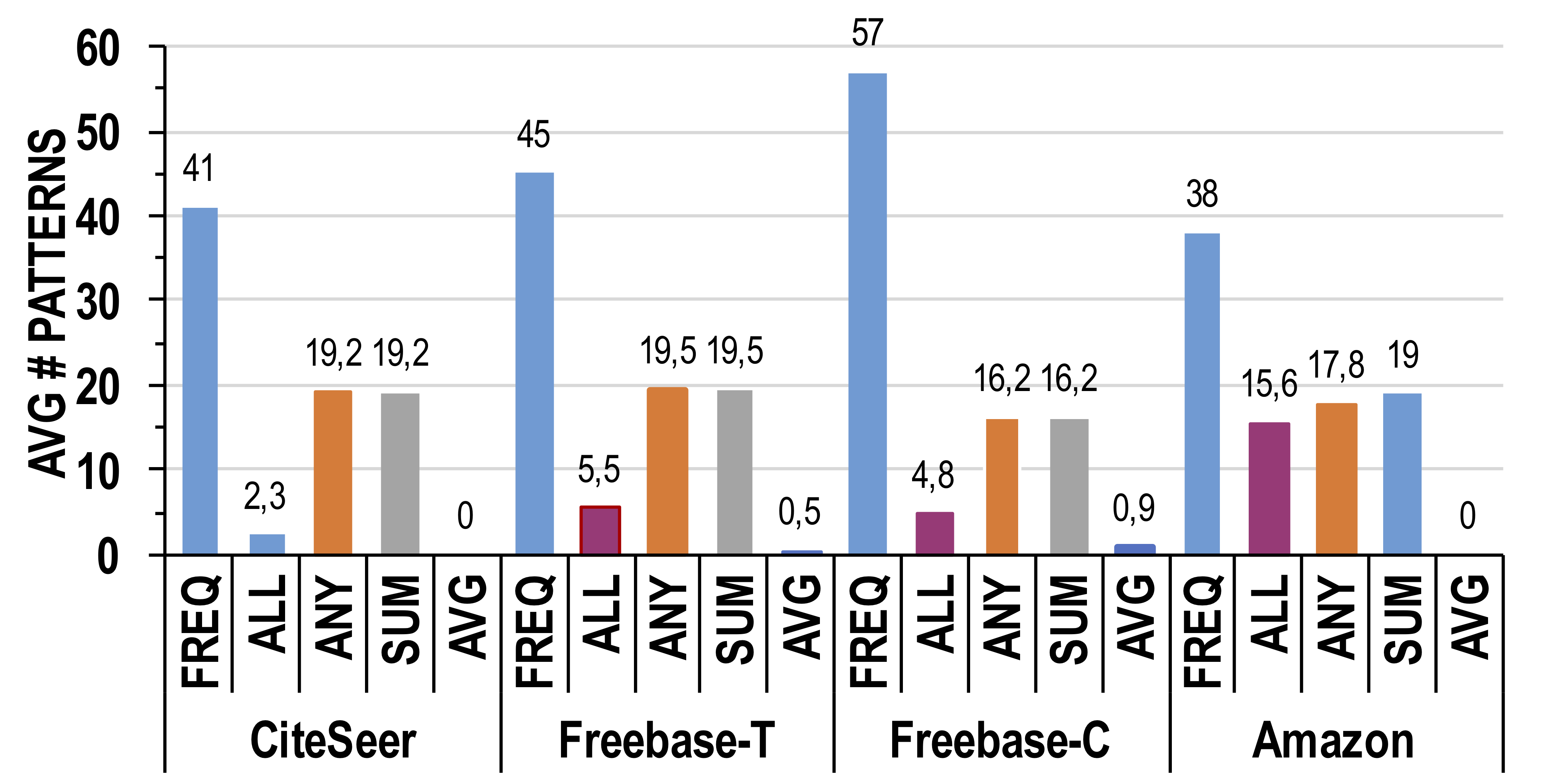
Pattern mining in graphs with preferences (weighted)
- Antimonotonic scoring functions for weighted graphs
- Mine patterns in multi-weight graphs (e.g., Amazon)
- Exact and approximate solutions for the problem
- Extensive evaluation on real graphs
Abstract
Graph pattern mining aims at identifying structures that appear frequently in large graphs, under the assumption that frequency signifies importance. Several measures of frequency have been proposed that respect the apriori property, pivotal to an efficient search of the patterns. This property states that the number of appearances of a pattern in a graph cannot be more than the frequency of any of its sub-patterns. In real life, there are many graphs with weights on nodes and/or edges. For these graphs, it is fair that the importance (score) of a pattern is determined not only by the number of its appearances, but also by the weights on the nodes/edges of those appearances. Scoring functions based on the weights do not generally satisfy the apriori property, thus forcing many approaches to employ other, less efficient, pruning strategy to speed up the computation. The problem becomes even more challenging in the case of multiple weighting functions that assign different weights to the same nodes/edges. In this work, we provide efficient and effective techniques for mining patterns in multi-weight graphs. We devise both an exact and an approximate solution. The first is characterized by intelligent storage and computation of the pattern scores, while the second is based on the aggregation of similar weighting functions to allow scalability and avoid redundant computations. Both methods adopt a scoring function that respects the apriori property, and thus they can rely on effective pruning strategies. We present a set of experiments to illustrate the efficiency and effectiveness of our approach.

Share this post
Reddit
LinkedIn
Email