Exemplar Queries: Give me an Example of What you Need
Davide Mottin, Matteo Lissandrini, Yannis Velegrakis, Themis Palpanas
PVLDB 2014, 7(5)
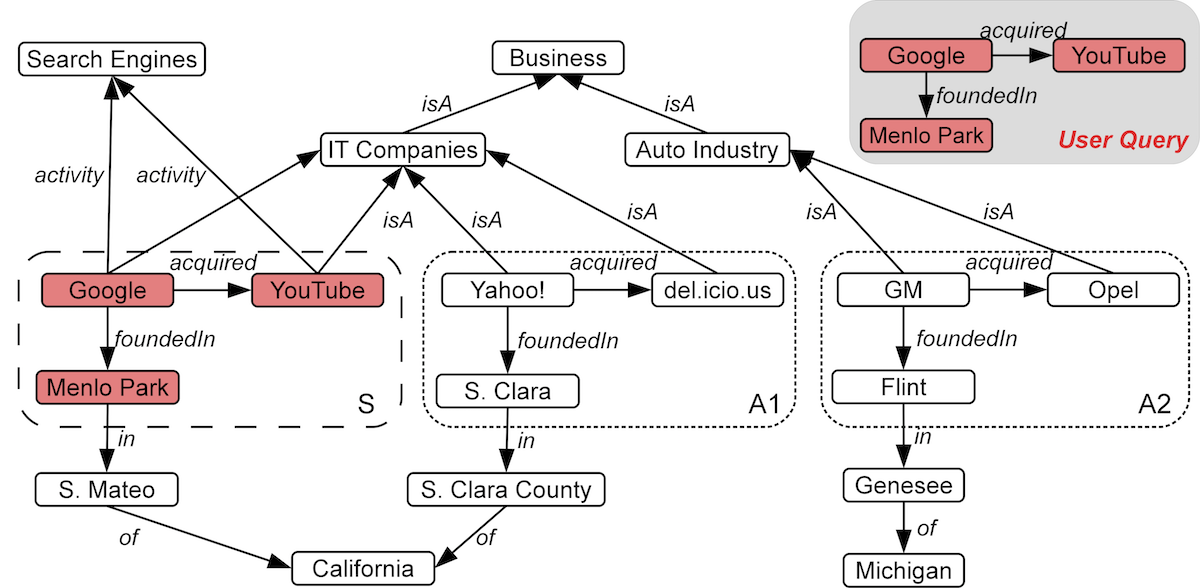
What if I know only an example of IT-companies acquisition?
TL;DR
Novel query paradigm that allows
- Finding answers to unknown query given an example
- Scales to Freebase1, the largest available knowledge graph
- Exhaustive and top-k approximate answers
- Answers in less than 1s
Abstract
Search engines are continuously employing advanced techniques that aim to capture user intentions and provide results that go beyond the data that simply satisfy the query conditions. Examples include the personalized results, related searches, similarity search, popular and relaxed queries. In this work we introduce a novel query paradigm that considers a user query as an example of the data in which the user is interested. We call these queries exemplar queries and claim that they can play an important role in dealing with the information deluge. We provide a formal specification of the semantics of such queries and show that they are fundamentally different from notions like queries by example, approximate and related queries. We provide an implementation of these semantics for graph-based data and present an exact solution with a number of optimizations that improve performance without compromising the quality of the answers. We also provide an approximate solution that prunes the search space and achieves considerably better time-performance with minimal or no impact on effectiveness. We experimentally evaluate the effectiveness and efficiency of these solutions with synthetic and real datasets, and illustrate the usefulness of exemplar queries in practice.

Share this post
Reddit
LinkedIn
Email