VERSE: Versatile Graph Embeddings from Similarity Measures
Anton Tsistulin, Davide Mottin, Panagiotis Karras, Emmanuel Müller
The WebConf 2018
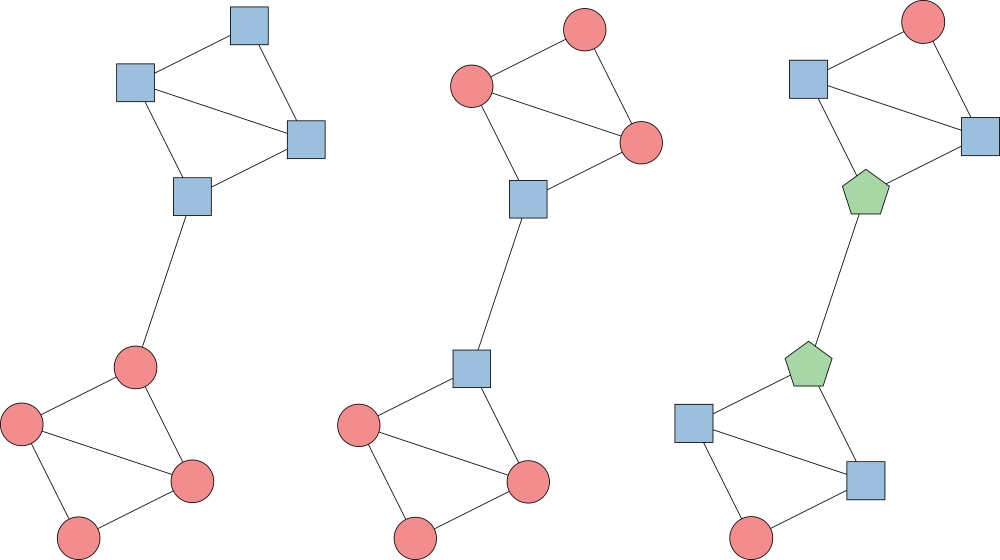
Can a single model capture three highlighted node properties?
TL;DR
State-of-the-art graph embedding algorithms are neural similarity matrix compression algorithms.
In this paper:
- We take the perspective of node similarities for node embedding.
- We show how previous works (DeepWalk, node2vec, LINE) implicitly utilize similarities.
- We develop an algorithm (VERSE) to efficiently preserve similarities.
- We create two VERSE versions: full that uses all node-to-node information, and sampled one that runs in linear time, yet provably converges to the full variant.
- We provide code in efficient C++ for both full and sampled version. We also provide efficient implementations of our baseline algorithms: DeepWalk and node2vec.
- We propose novel evaluation tasks (clustering, graph reconstruction) for graph embeddings.

Share this post
Reddit
LinkedIn
Email