Similarities and embeddings
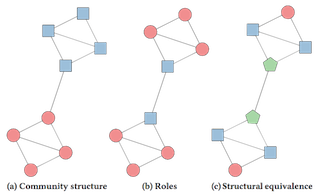
Does the graph structure conveys information on node / graph similarities?
Abstract
Graphs elegantly model a plethora of phenomena, from social interactions, to biological and chemical processes. Without any prior information comparing two graphs can only be done through notion of similarity. However, designing the right similarity for a certain task is a convolotued process which requires domain expertise and graph expertise. We propose self-learned similarity measures which scale to large graphs and are automatically harvested from the graph itself. Such measures can outperform traditional measures in different tasks, such as predicting future connections among users, understanding the effect of drugs, and detecting malicious users.

Share this post
Reddit
LinkedIn
Email